At Cohere Health, we’re focused on reducing provider abrasion by driving toward a touchless prior authorization process. In support of this mission, we leverage modern machine learning (ML) capabilities to identify key features from clinical documentation which can be used to assist in automatic approval of prior authorization service requests and to support efficient clinical review in cases that cannot be automatically approved.
The problem
Cohere receives thousands of prior authorization service requests every day. To support accurate review of this volume, we leverage ML to break down unstructured clinical documents into structured findings. We then combine these findings in deterministic health plan policy-based rules to automatically approve service requests. At face value, information extraction is a relatively simple and well-trafficked problem. If we want to identify whether a patient has knee pain based on an excerpt from a clinical note, a text classification model might provide sufficient resolution. If we want to extract the patient’s heart rate, there are many lightweight generative models or even rules-based parsers which can extract the values we care about. Historically, we have deployed each of these solutions: text classification models, simple extraction models, and rules-based parsers. However, as clinical use cases become more complex and nuanced, these solutions often fail to perform.
Specifically, we have found that leveraging naïve parsing solutions on clinical notes leads to a high rate of false positives. For example, a note might mention “patient should target a BMI of 25.” A naïve parser might extract 25 as the patient’s BMI, while in reality it wouldn’t be clinically appropriate to use that value in representing the patient’s state. Moreover, during clinical review, clinicians often care about and rely on relationships between clinical entities as opposed to the entities alone. As an example, a patient’s lab value might not be clinically useful without an associated date and unit. Other clinical findings are only useful if accompanied by metadata related to the finding (e.g., laterality of an injury or imaging finding).
Finally, for a given section of a document, there may be more than one valid finding. For instance, there may be five different blood pressure readings listed in close proximity. Such clinical concepts may only be useful when viewed in the context of the surrounding observations (e.g., to track change in a vital sign over the course of a visit).
Solution
Fortunately, modern instruction-tuned language models are capable of inferring concepts from clinical notes and outputting those concepts in structured formats, such as json or yaml. At Cohere, we leverage such technologies for “relation extraction,” the process of extracting multiple clinical concepts that are medically related to each other. Cohere’s Machine Learning team works closely with our clinicians and clinical analysts to configure and create models to extract nuanced clinical concepts.
Consider the following relational model configuration for an arthritis grading model, showing the fields to be extracted and a description of each field:

The first three fields could each be solved independently by classification-based approaches, but with relation extraction, we get the added benefits of being able to associate these findings with one another r and a date. We can also extract multiple findings per text span, meaning we can natively capture whether there is evidence of a specific arthritis instance improving or worsening, even if recorded in a single block of text.
Consider the following example text span, which could appear in a clinical note and its subsequent relation extraction finding:
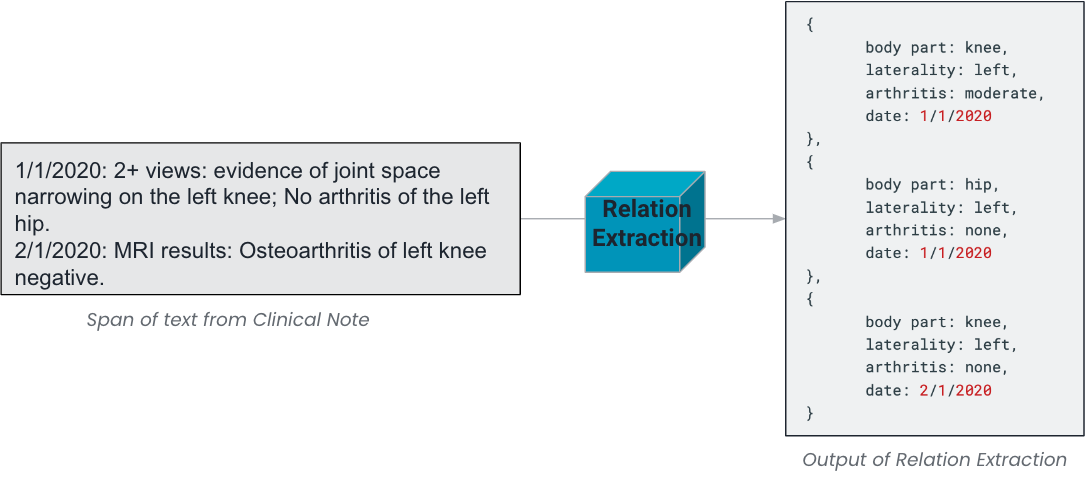
In certain use cases, language models are smart enough to reason about the text, enabling insights beyond verbatim extraction; this feature enables these models to perform text classification tasks as well as simple extraction tasks. In this example, the relation extraction approach “extracts” complete arthritis information, even when severity is not explicitly mentioned. The moderate arthritis finding was inferred leveraging historical examples or context within the prompt, associating joint space narrowing with moderate arthritis.
Application at Cohere Health
To provide value in policy-based decisioning rules, clinical concept extraction needs to be reliable and comprehensive. At Cohere, we have observed via experimentation that fine-tuned small language models (SLMs) can reliably extract nuanced clinical concepts with the high precision needed to support decisioning. To fine-tune SLMs, we work with in-house clinicians, who are experts in their clinical areas, to configure models and collect clinical annotations. With high quality training data and the use of modern language models, there is a terrific opportunity to reliably extract clinical concepts from unstructured text at scale.