
At Cohere Health, we stand at the forefront of improving healthcare management, applying research and technology to review medical requests accurately and improve patient outcomes. Our machine learning (ML) capabilities play a crucial role in extracting and processing information from clinical documentation based on industry guidelines, which enable precise reviews and timely interventions.
To support these capabilities, we need robust infrastructure to productionize ML solutions at scale. Cohere’s Machine Learning and Data Platform teams recently introduced a new inference service called SID, which stands for Single Instance Deployment. SID enables seamless deployment and management of ML models, facilitating rapid scaling and efficient resource utilization. Below, we’ve outlined the journey of ideating, implementing, and rolling out SID to advance our ML capabilities and deliver thousands of clinical predictions every minute.
Previous state and motivation
In ML-enabled systems, software applications typically act as clients requesting predictions from ML servers to achieve specific business objectives. For example, at Cohere, business objectives might include determining whether a patient uses nicotine or if they have undergone diagnostic imaging prior to surgery. The ML tasks to support these objectives involve embedding and classifying text spans from PDF files, using abstract data representations like tensors and NumPy arrays. This dichotomy requires integrating ML services into a larger ecosystem and defining the responsibilities of Research teams, Platform Engineering groups, and the interfaces between them.
Before SID, our ML models were deployed as event-based microservices responsible for fetching data from business APIs, making predictions, and saving the results for the core application. The Platform team set up messaging buses, developed CI/CD pipelines, and published SDKs to facilitate the containerization and deployment of these microservices.
Although this framework enabled ML scientists to quickly package and release models to production, it encountered some of the challenges described in “Hidden Technical Debt in Machine Learning Systems“. As the number of models grew, the following inefficiencies became apparent:
- Eroded boundaries: When an alarm went off, platform engineers, application developers, and ML researchers had to collaborate to diagnose the issue, leading to delays.
- Proliferation of glue code: There was an increase in utility scripts and libraries for cross-cutting concerns like preprocessing text or logging metrics. These libraries often lacked clear documentation, resulting in low adoption and the creation of even more similar scripts.
- Disjointed research efforts: Different research teams tackled similar problems using various ML frameworks, resulting in a wide range of algorithms and tools that were difficult to operate effectively in production.
To address these challenges, we drew inspiration from industry-leading ML platforms, like DoorDash’s inference service and AWS Sagemaker’s model hosting patterns. These examples guided our redesign, enabling scientists to efficiently ship ML solutions to production while keeping infrastructure footprint and operational costs under control.
Introducing SID’s new architecture
SID’s architecture includes a generic inference service, a model store, and prediction microservices. The inference service manages configurations and orchestrates the prediction workflow, interacting with a span service to retrieve data and a monitoring service for telemetry. To deploy a model—like one that classifies if a patient is a nicotine user—an ML scientist simply uploads a model weights file to the model store and a model configuration file to the inference service. The configuration file specifies how to fetch data, call the prediction service, and transform the raw prediction, allowing the new model to be released without any additional infrastructure.
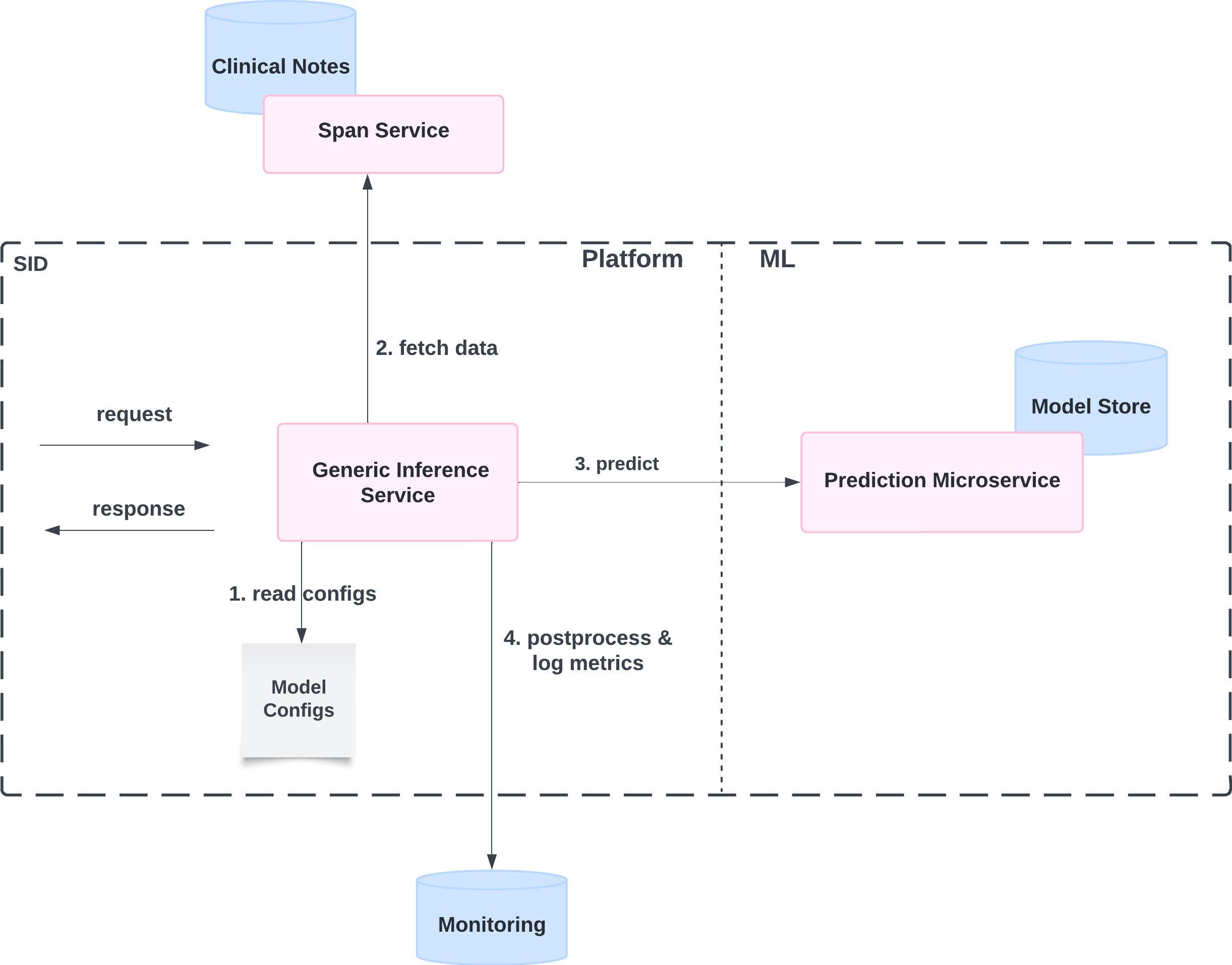
Figure 1: High-level architecture of SID Inference Service
Example request lifecycle
The following steps outline a request’s lifecycle for the ConservativeTherapy prediction task, which classifies evidence of conservative therapy in a clinical document.
- Model configuration: The inference service uses the model’s configuration file to determine preprocessing logic, prediction microservice routing, and post-processing requirements.
- Data preprocessing: Based on the configuration, it calls the Span search service in a RAG-style manner to retrieve text spans relevant to Conservative Therapy. This ensures that only contextually pertinent information is shown to the model, enhancing efficiency and accuracy. Details on how the span service converts clinical files to text and retrieves relevant text spans will be covered in a future article.
- Prediction: The preprocessed data is then routed to the prediction microservice that hosts the ConservativeTherapy model. The model classifies the text into specific categories such as activities of daily living, lifestyle modification, and assistive bracing device.
- Post-processing: Finally, the prediction is converted to a standard data schema (as defined in the configuration file), logged for monitoring, and returned to the caller.
Implementation highlights: Prediction microservices
At the heart of SID are the prediction microservices, designed to handle numerous medical language tasks with minimal infrastructure. We made two key design decisions to balance customization and flexibility with standardization. These decisions allow us to adapt the existing microservices to address new medical questions and, when necessary, deploy new microservices that integrate seamlessly with SID’s inference stack:
- Fine-tuned model adapters
We adapt large pre-trained models for specific tasks, employing LoRA (Low-Rank Adaptation) adapters for efficient model fine-tuning. This approach leverages a single large language model (LLM) with small, task-specific layers that are fine-tuned on a small percentage of the model’s weights. During inference, the prediction microservice can quickly switch adapters based on the request, avoiding the cold start complexities of loading entire models. Figure 2 illustrates the service activating the ConservativeTherapy adapter to serve the prediction. This setup runs a single base model instance per server with multiple adapters loaded in memory, offering flexibility and efficiency. To cover a new medical use case, we simply train a new adapter without risk of regression in the other tasks. - Decoupled prediction microservices
The generic inference service routes prediction tasks to separate prediction microservices. This decoupling allows the Platform team to deploy dedicated servers optimized with the appropriate environment and computational resources for specific machine learning algorithms. For example, classification tasks (e.g., classifying a patient as a nicotine user) run on CPU-backed instances with a small language model and fine-tuned adapters, while extraction tasks (e.g., date and dosage of a member’s last pain injection) utilize GPU-backed servers with a larger base model and corresponding adapters.
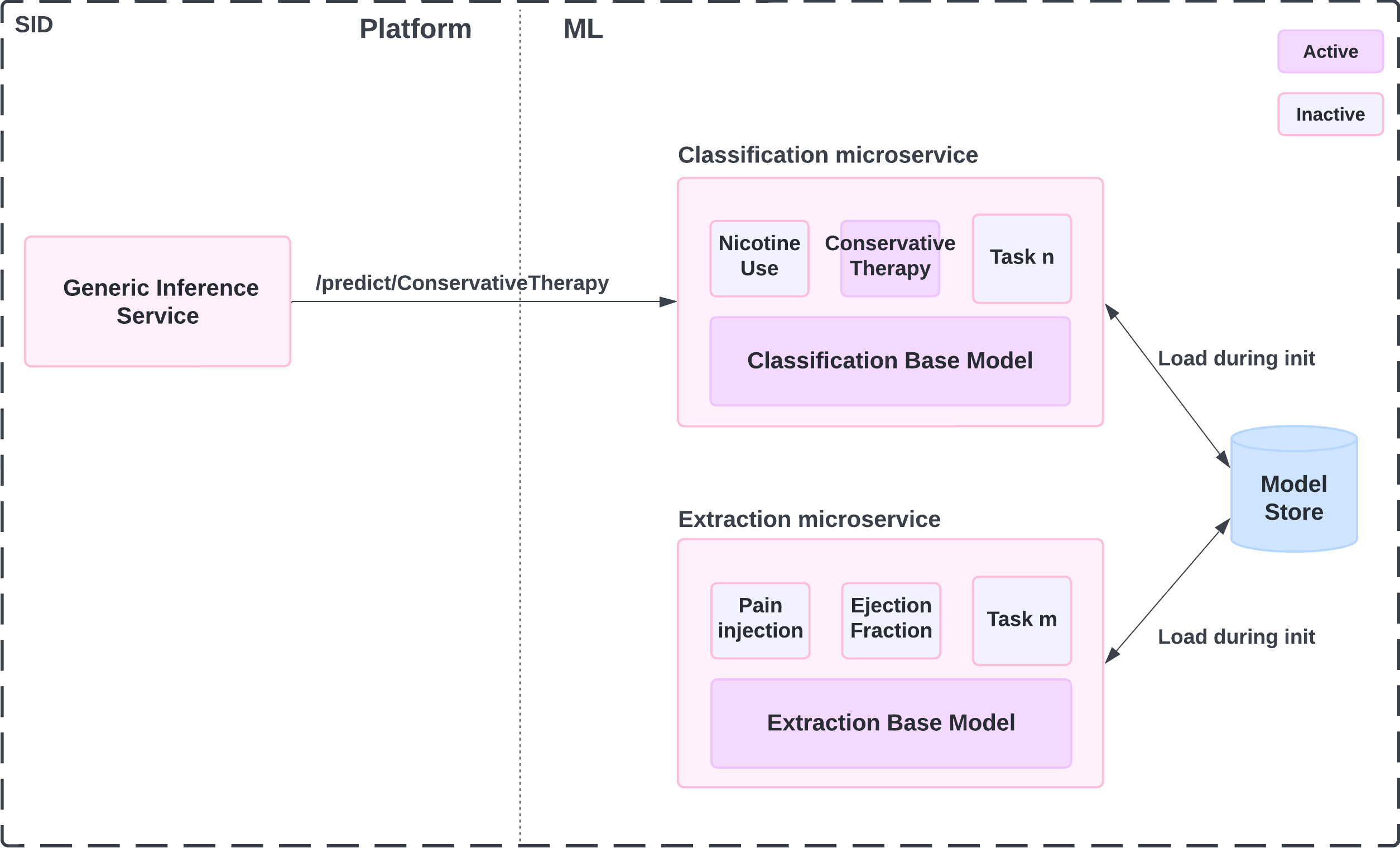
Figure 2: Anatomy of the prediction microservice during an inference request for ConservativeTherapy classification
Rolling it out and early results
SID was initially deployed in background mode alongside the legacy model services, using the same event triggers and logging predictions. This phase allowed us to validate its functional correctness and test scaling configurations with real production traffic. We gradually shifted traffic to SID, starting with classification models and then expanding to other clinical projects.
Currently, SID houses 18 models in production, covering over 80 medical segments and delivering more than 3,000 predictions per minute. Its robust auto-scaling adjusts resources to meet demand peaks automatically, and its monitoring systems detect issues in both the prediction and business stages. While this new process requires teams to follow a standardized development and deployment recipe, it has proven versatile across various problem spaces and has significantly enhanced our teams’ agility.
Acknowledgments
We thank Cohere’s Machine Learning and Data Platform teams for their involvement in designing and building SID. These collaborative efforts continue to push the boundaries of what our AI-enabled systems can achieve in healthcare.
If you’re looking for a new challenge and want to help us revolutionize healthcare, check out the current career opportunities on Cohere’s Engineering team.
