
At Cohere Health, our key focus is to accelerate care access and reduce provider abrasion by driving towards a touchless prior authorization process. In support of this mission, we leverage modern machine learning (ML) capabilities to identify key attributes from clinical documentation that can be used to automate components of the prior authorization lifecycle.
Today, a significant portion of prior authorization requests and clinical documentation from healthcare providers are faxed to health plans. This requires plans to maintain costly fax intake operations to triage inbound submissions and digitize administrative and clinical attributes from fax documents. While technological solutions exist, many require manual data entry that increases the risk of capturing incomplete or inaccurate data. This causes friction with providers and leads to delays in authorization request processing and patient care. In contrast, Cohere Health’s fax intake solution uses ML to extract these attributes and automatically assemble digital prior authorization service requests in our portal, streamlining operations. In this article, we discuss the technologies supporting Cohere’s fax pipeline and how they enable touchless prior authorization.
The problem
Each day, Cohere manually processes thousands of incoming fax requests, with each fax averaging 17 pages and some containing upwards of 200 pages. With document formatting and fax length varying from health plan to health plan and request to request, manual processing of these faxes demands high attention to detail and consumes hundreds of valuable staff hours per month. ML presents a compelling opportunity to not only automate portions of this workflow, but also enhance staff efficiency where human review is still needed.
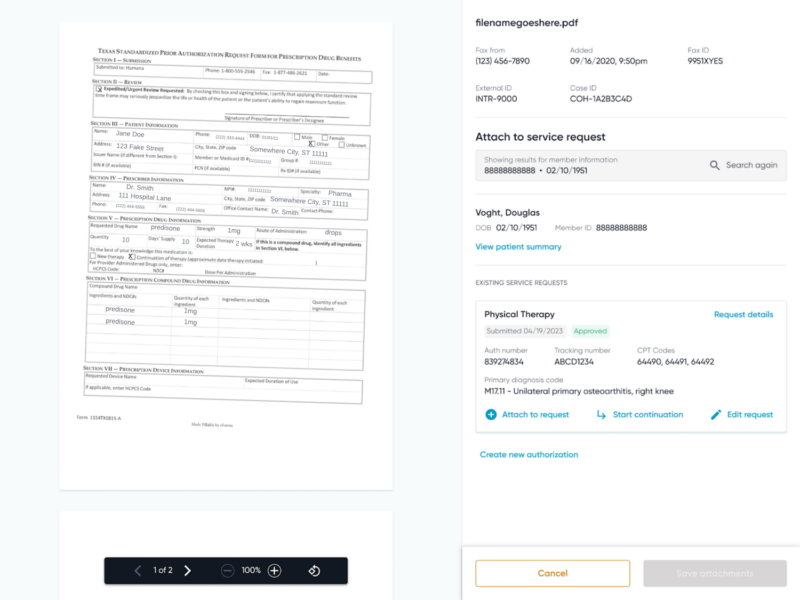
Figure 1: Example fax intake workflow screen showcasing the fax received on the left and the associated service request on the right.
The challenge
To create a digital prior authorization service request from faxes, approximately 40 administrative attributes–such as patient identifiers, provider details, and the procedure requested–must be extracted from the fax documentation. In the absence of automation, our intake specialists review each page of the fax documentation to extract each administrative attribute and manually create a service request within the Cohere portal (Figure 1). While designing and implementing an ML solution to automate prior authorization service request creation from faxes, we consider the following three criteria:
- Generalizability: A solution that works for varying formats, types, and lengths of fax attachments we receive from multiple clients (health plans);
- Scalability: A solution that is easy to build and deploy in a cost-effective way, with an increasing number of health plans and authorization volume; and
- Precision: A solution that is as accurate or more accurate than intake specialists to enable touchless automation.
In pursuit of such a solution, Cohere’s ML team collaborated with intake specialists to develop a deep understanding of their processes and adopted a data-centric approach. While we initially considered traditional ML algorithms, we quickly realized that no single algorithm could solve all our fax efficiency challenges. We then explored state-of-the-art large language models, but found that even with prompt engineering and fine-tuning, they sometimes lacked the precision needed to capture the nuances in medical data. After extensive research and experimentation, we developed a mixed-model approach that combined the strengths of various algorithms to enable our current fax intake pipeline.
Our Solution
Optimizing our fax workflow called for a system that would extract administrative values from documents with expert knowledge and nuance for precision, yet generalize across different types of fax documents and be scalable enough to keep pace with Cohere’s rapid growth. We developed an ML-powered fax intake pipeline that employs scalable and generalizable ML models to extract and predict the administrative fields, accompanied by field-specific or health plan-specific configurations to achieve high precision.
Our fax pipeline (Figure 2) consists of the following steps:
- OCR: Text from the incoming PDF is extracted for downstream consumption using OCR (optical character recognition)
- Value prediction: Generalizable ML models ingest the OCR’ed text and predict the values for the 40+ administrative fields needed to build a service request
- Configurable prediction refinement: The predictions are refined and validated against various quality standards relevant to the particular fields or health plans, delivering exceptional precision
- Prediction consumption: Refined predictions are sent to user-facing applications and replace manual workflows where possible

Figure 2: High-level steps of the fax intake pipeline
The models are hosted on AWS Lambdas with auto-scaling capabilities, chained together with the other pipeline components within a State Machine and orchestrated by step functions. These infrastructure choices ensure that our pipeline is optimized for plan-specific configurations and fluctuations in volume while keeping costs low, contributing to the scalability of our overall solution.
[Component 1] Extracting text with OCR
As the first step in our pipeline, the OCR component is crucial to the success of downstream modules. It leverages powerful language and vision ML models to extract raw text as well as structured metadata, which can be leveraged by downstream models for field value extraction and classification. Our OCR infrastructure is a key contributor to making fax intake more efficient.
[Component 2] Predicting administrative fields
As mentioned above, the OCR’ed text from incoming fax documentation is used as input to a variety of models that are trained on data labeled by intake specialists to predict the 40+ administrative fields needed to build a service request (Figure 3). Those administrative fields each fall into one of three task categories: direct extraction, inferred extraction, and classification.
Direct Extraction
Direct extraction involves extracting specific values verbatim from faxes, such as parsing 10-digit National Provider Identifiers (NPIs) or CMS ICD-10 codes. Our selected system handles these well-defined fields more effectively than other best-in-class approaches and optimizes on recall of extracted values. While it also yields a higher false positive rate, we mitigate this by applying heuristics and validation against databases to filter out incorrect values, as described in the refinement section below.
Inferred extraction
Inferred extraction also handles tasks that pick values directly from fax documentation. Unlike direct extraction, these fields–such as patient names or start of care dates–are more ambiguous and require an understanding of context and relationships in text to pinpoint the value that should be inferred. For example, distinguishing between provider and patient names requires understanding who is providing versus receiving care in the document’s context. We therefore employ models that excel at understanding semantic relationships and capture nuance to perform inferred extraction tasks.
Classification
The last category of fields falls under classification. These fields require synthesizing all relevant text and other metadata features from the given fax attachments into one value. For example, the urgency of an authorization can be inferred through the context provided in a request’s attached clinical notes, such as the intent of the request or specific language that is used. Our classification pipeline transforms the OCR-extracted text into features that are then used to probabilistically associate each request with the appropriate binary or multiclass label. Each prediction is also accompanied by a probability score used in the subsequent refinement step.

Figure 3: Field prediction pipeline
Each of the models discussed above can be easily retrained or adjusted to support any requirement changes or new clients–which can cause a shift in the data distribution–supporting the generalizability and scalability of our solution.
[Component 3] Refining predictions
After inference, our pipeline employs a multi-step refinement process to clean and validate model predictions. Each field undergoes specific post-processing and validation checks relevant to the requirements and usage of that field, such as formatting adjustments, database verification, and confidence filtering. This refinement process deliberately trades coverage for precision, ensuring that only high-confidence, validated predictions are used to populate administrative fields. It generalizes well as the validations and heuristics applied follow industry standards or common sense, and field-specific business rules can be adjusted as needed.
[Component 4] Consuming predictions
Our refined predictions contribute to the efficiency, quality, and consistency of our fax intake process through two levels of automation:
- Full automation: When all administrative fields are successfully refined and validated, a fax service request will automatically be generated, completely bypassing manual review. Full automation is depicted in the left pathway in Figure 4. This optimal outcome removes the need for a human touch and significantly reduces overall processing time.
- Partial automation: When only some fields pass refinement, we pre-populate these validated values in the user interface while flagging the remaining fields for manual completion. Partial automation is depicted in the right pathway in Figure 4. This hybrid approach expedites case build by reducing manual data search and entry, while maintaining accuracy through human verification of uncertain fields.
Both pathways improve operational efficiency, with full automation providing the greatest time savings, and partial automation streamlining the necessary manual work.
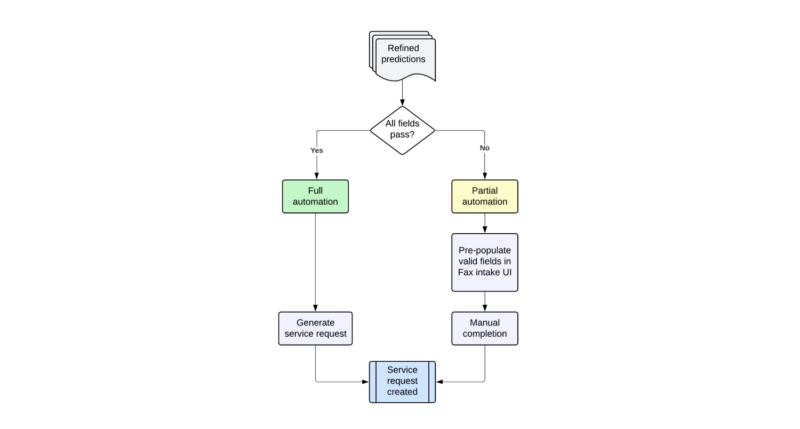
Figure 4: Fax automation and integration workflow
Putting it all together
The components introduced above make up Cohere Health’s generalizable, scalable, and precise fax intake pipeline, harmonizing to reduce inefficiency and increase the quality and consistency of our fax intake process. After an incoming fax request is OCR’ed, our 3-pronged modeling approach tackles extraction, inferred extraction, and classification of the document text flexibly and accurately, generating predictions for each of the 40+ administrative fields. Those raw model outputs are then polished by our post-processing logic to ensure high quality; the refined predictions are then applied to full or partial automation tasks as appropriate, such that each fax request is handled as quickly and meticulously as possible.
Impact
Approximately 38% of faxes received by Cohere are now processed automatically using values extracted by our fax pipeline. Of the remaining faxes requiring manual processing, 90% are partially automated, enabling intake specialists to handle faxes at an increased rate and with higher accuracy. The combination of full and partial automation has allowed Cohere to cut the average intake time for faxes in half.
These improvements deliver dual benefits: significantly boosting operational efficiency, while enhancing the quality and consistency of our intake process. The reduction in manual data entry saves time and reduces the potential for human error, leading to more reliable case creation and the potential for authorization auto-approval in minutes.
Future directions
While our current pipeline effectively processes OCR’ed text, it still has room for improvement in extracting information from other document metadata. Visual elements like checkboxes, radio buttons, and form layouts are rife with clinical information. We are currently experimenting with more powerful multimodal LLMs that can understand both text and visual elements, which have proven to be extremely promising for our use case, and enables us to capture complementary request details in form structure and visual indicators. By incorporating previously unused visual data, we expect to improve extraction accuracy and increase our automation rates.
As we continue to innovate and expand our capabilities, we remain focused on our core mission: reducing administrative burden while improving the speed and accuracy of prior authorizations.
Conclusion
By taking a data-centric ML approach and closely collaborating with domain experts, we have created a system that can handle the complexities of fax intake with flexibility and reliability. The described modeling methodologies in combination with validation and refinement steps accomplish all crucial fax intake and administrative field extraction tasks, meeting our requirements for a generalizable, scalable, and precise solution. Optimizing our fax workflow delivers significant value on multiple fronts: reducing operational costs for prior authorization submissions; accelerating patient care delivery; and improving quality of care. These improvements ultimately help Cohere Health achieve its mission: to reduce provider abrasion and support efficient clinical review within the prior authorization process.
If you’re looking for a new challenge and want to help us revolutionize healthcare, check out the current career opportunities on Cohere’s Engineering team.
